¶ Instrukcja korzystania i uruchamiania przykładów
Środowisko Jupyter notebook jest w dużej mierze używane do interaktywnego, eksploracyjnego programowania analizy danych i wizualizacji danych. Pozwala na bezpośrednie interakcyjne uruchamianie skryptów w wirtualnym środowisku dostępnym poprzez przeglądarkę internetową. Środowisko jest uruchomione na zasobach Ośrodka Kształcenia na Odległość Politechniki Warszawskiej. Do zalogowania wymagane jest posiadanie aktywnego konta CAS na platformie Leia. Pliki użytkownika są przechowywane lokalnie na serwerze Jupyter w Ośrodku Kształcenia na Odległość Politechniki Warszawskiej.
W celu uruchomienia narzędzia należy kliknąć w link "Narzędzie Jupyter notebook" zamieszczony w kursie w sekcji "Środowiska uruchomieniowe i narzędzia".

Po kliknięciu w link zostanie uruchomione narzędzie "Jupyterhub" w wewnętrznym oknie platformy pozwalające na zarządzanie swoim wirtualnym serwerem.
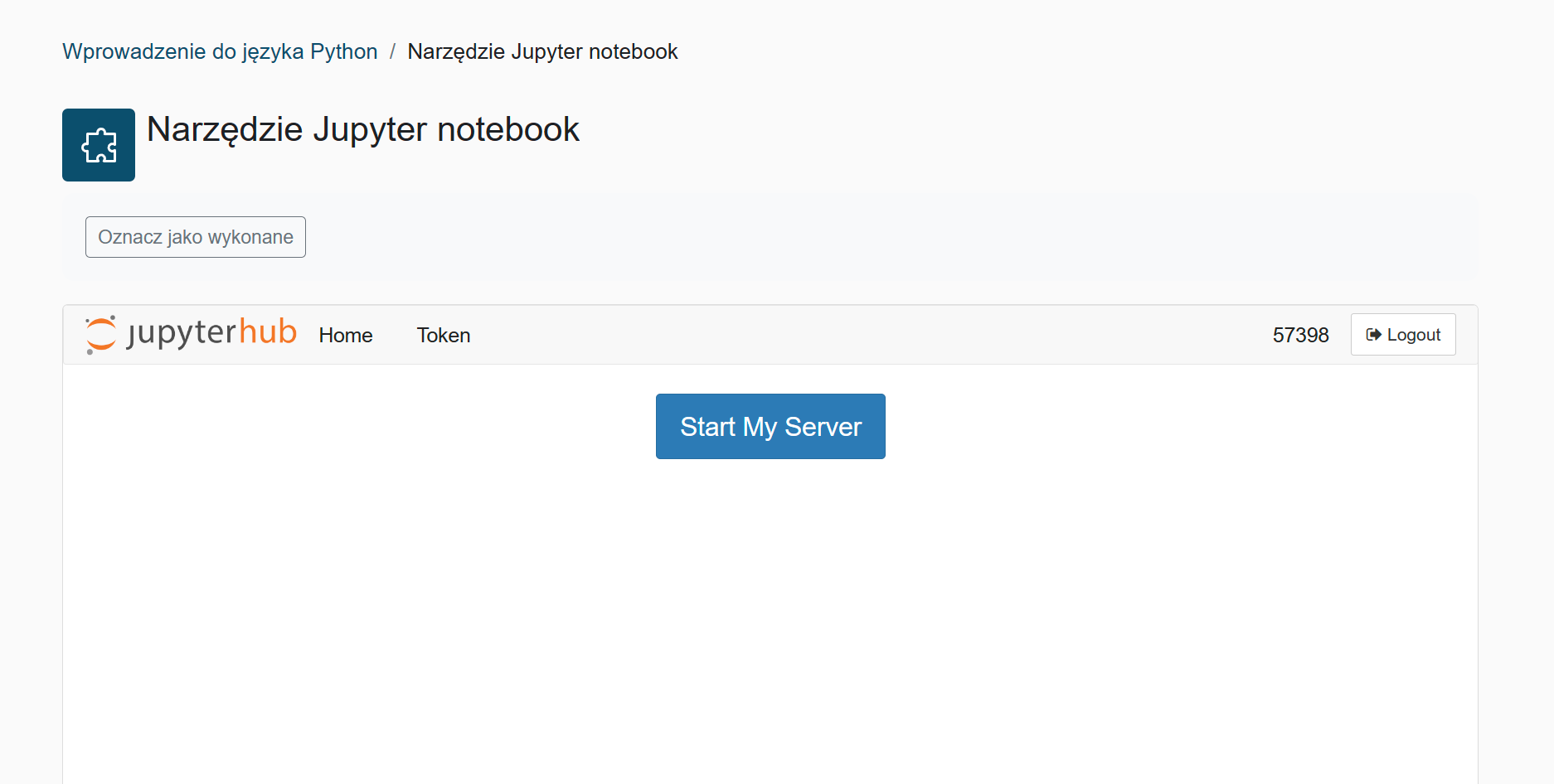
Przedstawione na rysunku nr 2 okno powala na zarządzanie serwerem. Jeżeli nie mamy uruchomionego wirtualnego środowiska (sytuacja przedstawiona na rysunku) należy nacisnąć przycisk "Start My Serwer". Po chwili powinien załadować się serwer. Jeżeli mamy już uruchomiony serwer wirtualny otrzymamy okienko jak na rysunku nr 3.
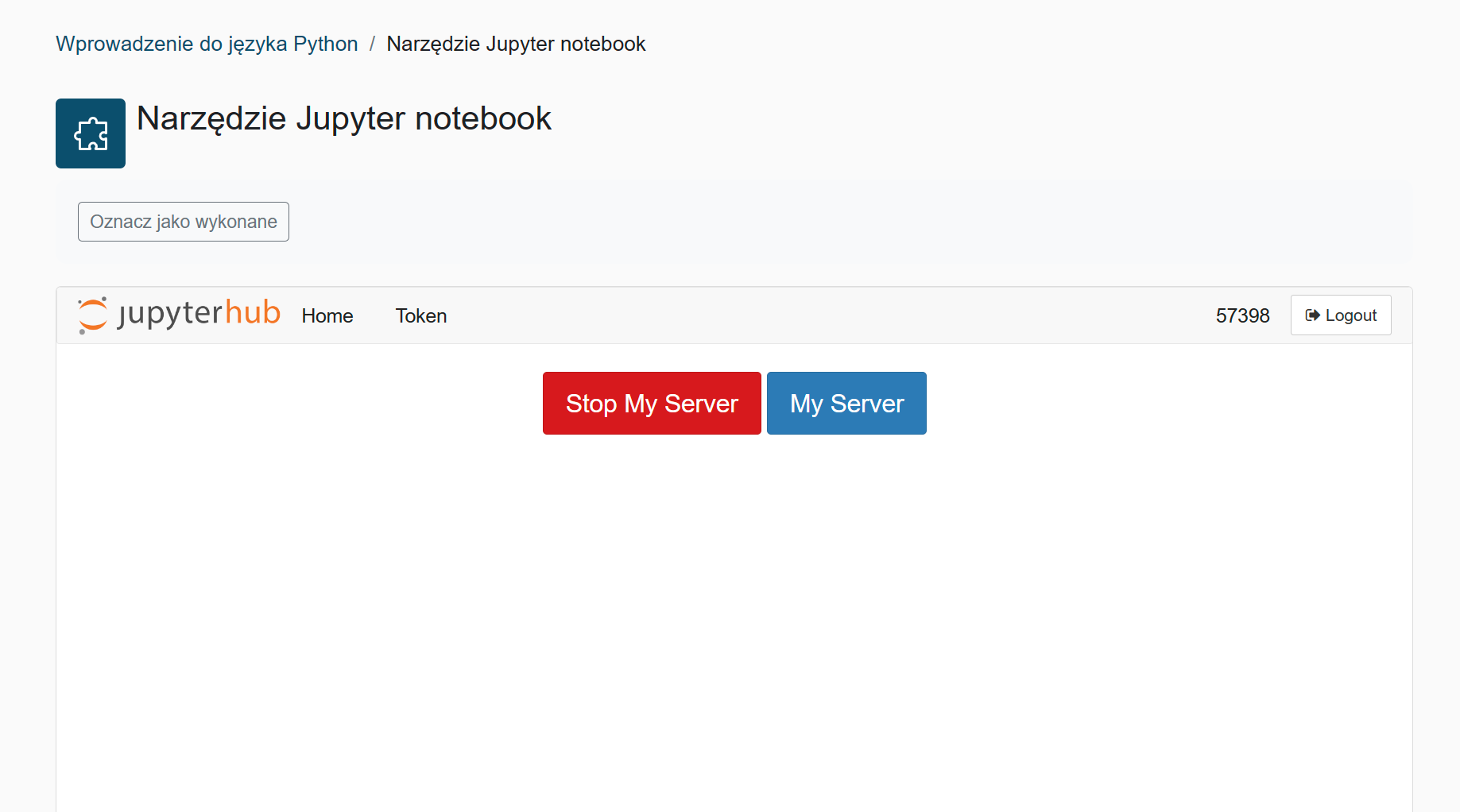
Z tego poziomu możemy "zatrzymać" środowisko wirtualne lub przejść do niego naciskając przycisk "My Serwer"
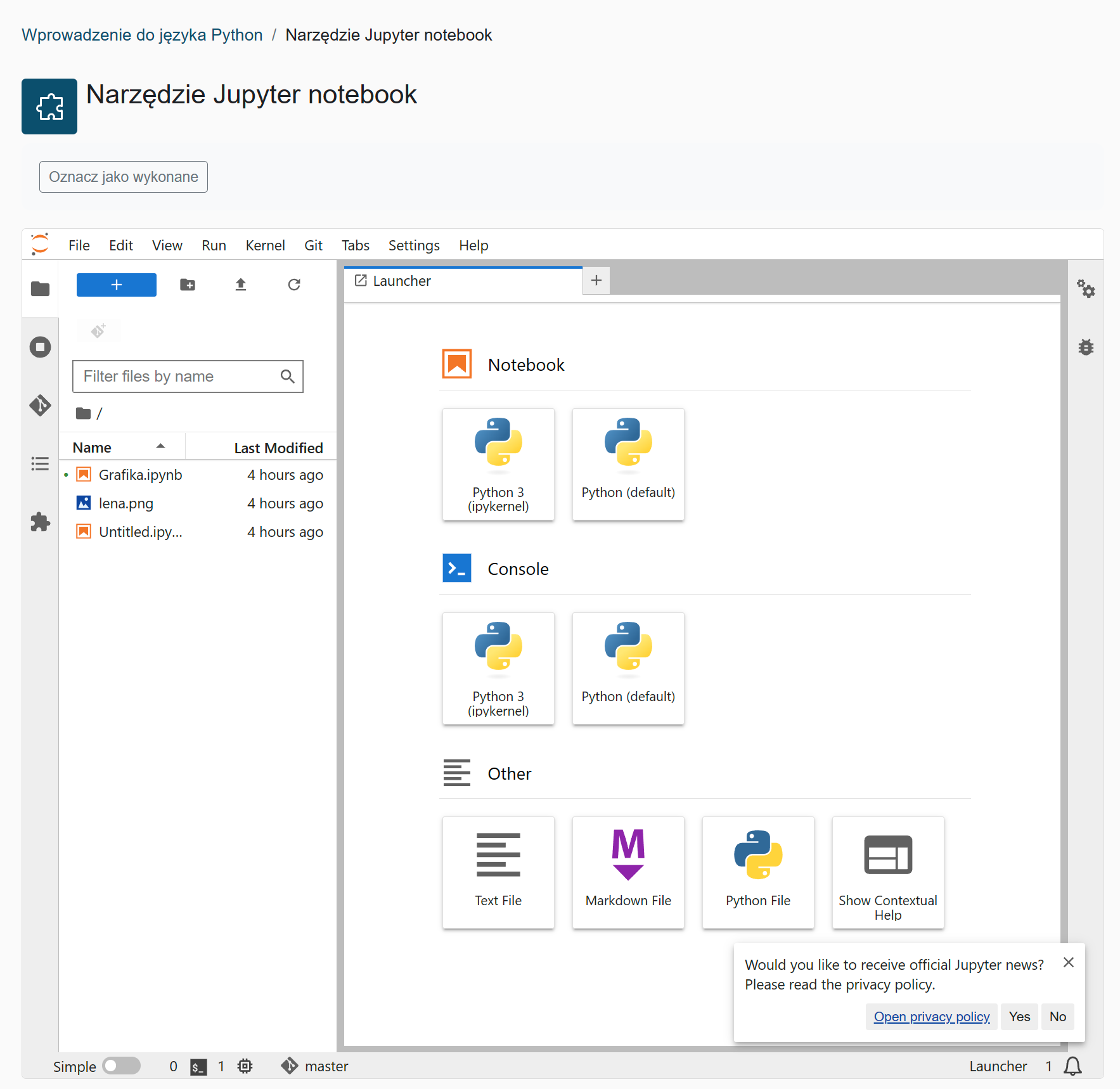
Obszar roboczy środowiska możemy podzielić na trzy obszary:
- pasek funkcji znajdujący się z lewej strony, domyślnie jest wyświetlany obszar plików użytkownika (ikonka folderu),
- górne menu funkcyjne,
- obszar z zainstalowanymi środowiskami uruchomieniowymi Podzielony na Notebook i Console (Python default oraz Python 3) oraz inne pliki.
Nas interesuje Notebook w którym można tworzyć opis oraz budować kod i go uruchamiać zapisując wyniki bezpośrednio w notebooku.
W ramach kursu zamieszczonych zostało wiele przykładowych plików z kodem jak i notebookami. Po pobraniu pliku z rozszerzeniem ipynb na swój komputer można go wgrać na swoje konto aby móc na nim pracować. Pierwszą metodą jest przeciągnięcie pliku z folderu z loklanymi plikami do zaznaczonego szarą linią obszaru plików.
Drugą, tradycyjną metodą jest użycie ikonki  w celu otwarcia tradycyjnego okienka wgrywania plików.
w celu otwarcia tradycyjnego okienka wgrywania plików.
Po wgraniu plików pliku jest on dostępny w obszarze plików użytkownika. W obszarze plików użytkownika można tworzyć katalogi co pozwala na organizację przestrzeni plikowej.
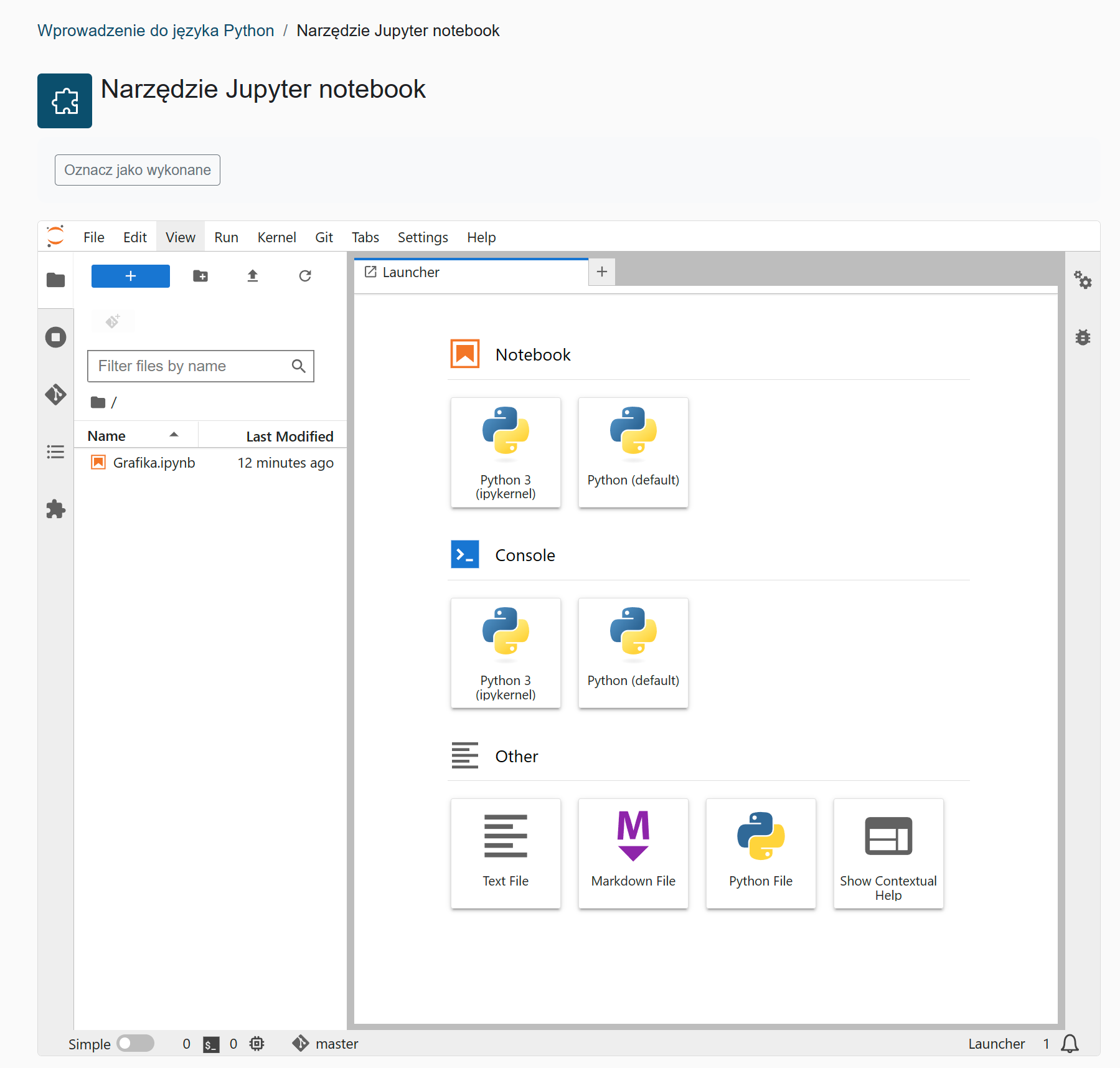
Po kliknięciu w plik zostanie załadowany plik do obszaru roboczego (w tym przypadku jest to plik nootebooka).
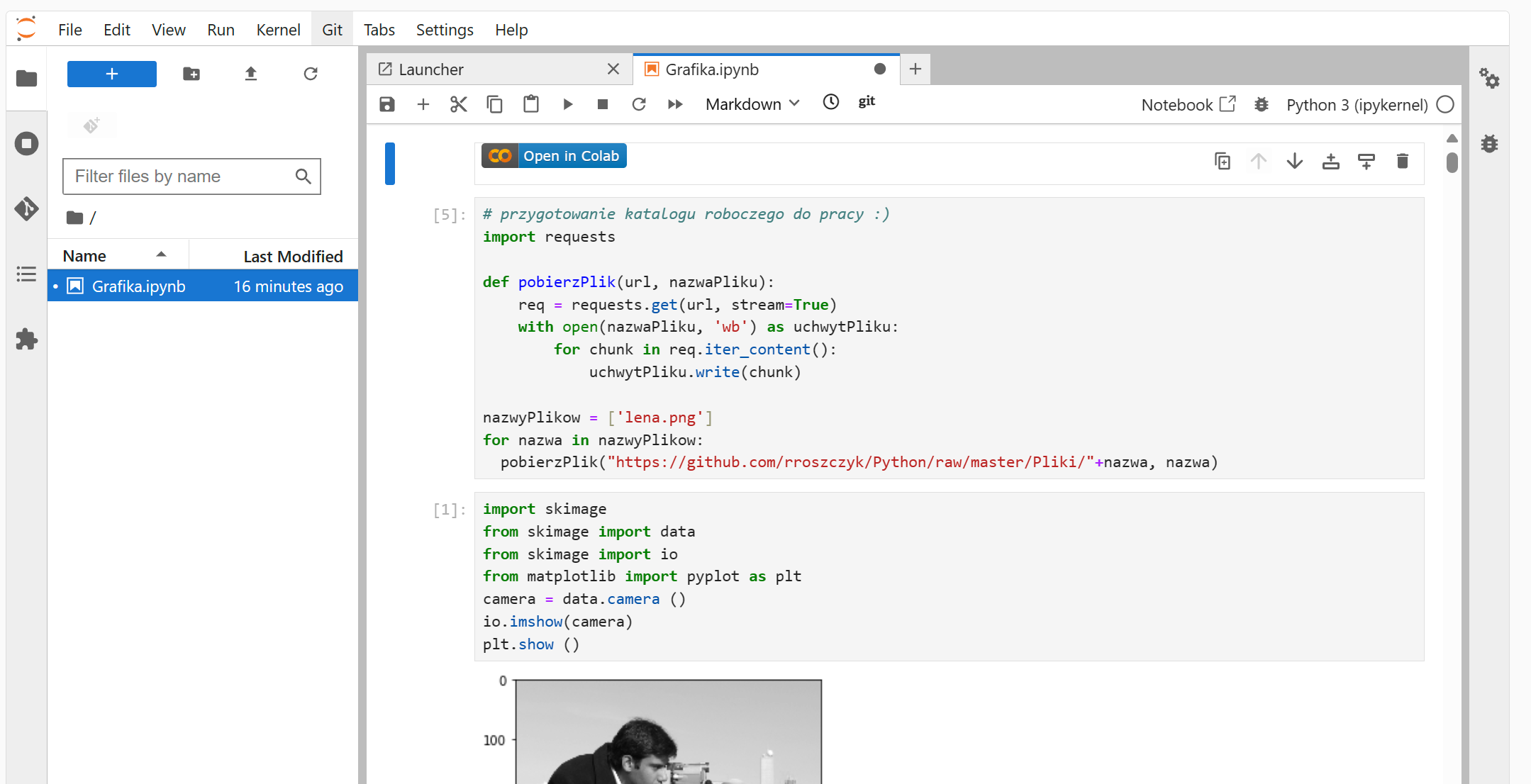
Kod z załadowanego notebooka jest wykonywany automatycznie po wczytaniu pliku. W każdej chwili możemy dokonywać zmian w kodzie i za pośrednictwem menu funkcyjnego notebooka  możemy ten kod uruchomić.
możemy ten kod uruchomić.
¶ Zbiór przykładów
Celem repozytorium jest stworzenie największego katalogu gotowych do produkcji szablonów Jupyter Notebooks. Dzięki tym szablonom tworzenie produktów danych (analitycznych dashboardów, automatyzacji/silników AI i innych) staje się łatwe.
Każdy z tych szablonów opiera się na spójnych ramach mających na celu przyspieszenie procesu kodowania. Chociaż szablony te zaprojektowano z myślą o łatwości użycia, niektóre z nich mogą wymagać do konfiguracji umiejętności związanych z analizą danych, szczególnie w przypadku tych, które łączą się z narzędziami innych firm za pośrednictwem interfejsu API. Szablony te mogą działać niezależnie, ale służą również jako integralne składniki produktów danych. Uważaj je za niezbędne części potrzebne do złożenia „silnika samochodowego”. Rozwijając te szablony i zapewniając ich samodzielną funkcjonalność, usprawniamy proces tworzenia produktu danych, ponieważ rozumiemy już działanie niektórych jego części.
Wszystkie szablony są łatwo dostępne w GitHubie lub poprzez Naas Search.
Zbiór materiałów autora kursu - dr inż. Radosława Roszczyka Przejdź na Github